Lookup Tables: Alists and Plists(查找表:关联表和属性表)
In addition to trees and sets, you can build tables that map keys to values out of cons cells. Two flavors of cons-based lookup tables are commonly used, both of which I've mentioned in passing in previous chapters. They're association lists, also called alists, and property lists, also known as plists. While you wouldn't use either alists or plists for large tables--for that you'd use a hash table--it's worth knowing how to work with them both because for small tables they can be more efficient than hash tables and because they have some useful properties of their own.
除了树和集合以外,你还可以用点对单元来构建表将键映射到值上。有两类基于点对的查询表被经常用到,这两者都是前面章节里提到过的。它们是关联表(alist)和属性表(plist)。尽管它们都不能用于大型查找表(那种情况下你可以使用哈希表),但是值得去了解其使用方式,这既是因为对于小型的表而言,它们可以比哈希表更加高效,同时也是因为它们的一些专有属性十分有用。
An alist is a data structure that maps keys to values and also supports reverse lookups, finding the key when given a value. Alists also support adding key/value mappings that shadow existing mappings in such a way that the shadowing mapping can later be removed and the original mappings exposed again.
关联表是一种数据结构,它能将一些键映射到值上,同时也支持反向查询,并且当给定一个值时,它还能找出一个对应的键。关联表也支持添加键值映射来掩盖已有的映射,并且当这个映射以后被移除时原先的映射还可以再次暴露出来。
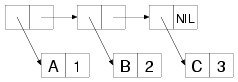
Under the covers, an alist is essentially a list whose elements are
themselves cons cells. Each element can be thought of as a key/value
pair with the key in the cons cell's CAR and the value in the CDR. For
instance, the following is a box-and-arrow diagram of an alist mapping
the symbol A to the number 1, B to 2, and C to 3:
从底层来看,关联表本质上是一个列表,其每一个元素本身都是一个点对单元。每个元素可以被想象成是一个键值对,其中键保存在点对单元的
CAR 中而值保存在 CDR
中。例如,下面是一个将符号 A 映射到数字 1、B 映射到 2,C
映射到 3 的关联表的方框和箭头图例:
Unless the value in the CDR is a list, cons cells representing the key/value pairs will be dotted pairs in s-expression notation. The alist diagramed in the previous figure, for instance, is printed like this:
除非 CDR 中的值是一个列表,否则代表键值对的点对单元在表示成 S-表达式时将是一个点对(dotted pair)。例如上图所表示的关联表将被打印成下面的样子:
((A . 1) (B . 2) (C . 3))The main lookup function for alists is ASSOC, which takes a key and an alist and returns the first cons cell whose CAR matches the key or NIL if no match is found.
关联表的主查询函数是 ASSOC,其接受一个键和一个关联表并返回第一个 CAR 匹配该键的点对单元,或是在没有找到匹配时返回 NIL。
CL-USER> (assoc 'a '((a . 1) (b . 2) (c . 3)))
(A . 1)
CL-USER> (assoc 'c '((a . 1) (b . 2) (c . 3)))
(C . 3)
CL-USER> (assoc 'd '((a . 1) (b . 2) (c . 3)))
NILTo get the value corresponding to a given key, you simply pass the result of ASSOC to CDR.
为了得到一个给定键的对应值,你可以简单地将 ASSOC 的结果传给 CDR。
CL-USER> (cdr (assoc 'a '((a . 1) (b . 2) (c . 3))))
1By default the key given is compared to the keys in the alist using
EQL, but you can change that with the standard combination of :key and
:test keyword arguments. For instance, if you wanted to use string
keys, you might write this:
在默认情况下,指定的键使用 EQL 与关联表中的键进行比较,但你可以通过使用
:key 和 :test
关键字参数的标准组合来改变这一行为。例如,如果想要用字符串的键,则可以这样写:
CL-USER> (assoc "a" '(("a" . 1) ("b" . 2) ("c" . 3)) :test #'string=)
("a" . 1)Without specifying :test to be STRING=, that ASSOC would probably
return NIL because two strings with the same contents aren't
necessarily EQL.
如果没有指定 :test 为 STRING=,ASSOC 将可能返回
NIL,因为带有相同内容的两个字符串不一定 EQL 等价。
CL-USER> (assoc "a" '(("a" . 1) ("b" . 2) ("c" . 3)))
NILBecause ASSOC searches the list by scanning from the front of the list, one key/value pair in an alist can shadow other pairs with the same key later in the list.
由于 ASSOC 搜索列表时会从列表的前面开始扫描,因此关联表中的一个键值对可以遮盖列表中后面带有相同键的其他键值对。
CL-USER> (assoc 'a '((a . 10) (a . 1) (b . 2) (c . 3)))
(A . 10)You can add a pair to the front of an alist with CONS like this:
你可以像下面这样使用 CONS 向一个关联表的前面添加键值对:
(cons (cons 'new-key 'new-value) alist)However, as a convenience, Common Lisp provides the function ACONS, which lets you write this:
但为了方便起见,Common Lisp 提供了函数 ACONS,它可以让你这样写:
(acons 'new-key 'new-value alist)Like CONS, ACONS is a function and thus can't modify the place holding the alist it's passed. If you want to modify an alist, you need to write either this:
和 CONS 一样,ACONS 是一个函数,因此它不能修改用来保存所传递的关联表的位置。如果你想要修改关联表,你需要写成这样:
(setf alist (acons 'new-key 'new-value alist))or this:
或者这样:
(push (cons 'new-key 'new-value) alist)Obviously, the time it takes to search an alist with ASSOC is a
function of how deep in the list the matching pair is found. In the
worst case, determining that no pair matches requires ASSOC to scan
every element of the alist. However, since the basic mechanism for
alists is so lightweight, for small tables an alist can outperform a
hash table. Also, alists give you more flexibility in how you do the
lookup. I already mentioned that ASSOC takes :key and :test keyword
arguments. When those don't suit your needs, you may be able to use
the ASSOC-IF and ASSOC-IF-NOT functions, which return the first
key/value pair whose CAR satisfies (or not, in the case of
ASSOC-IF-NOT) the test function passed in the place of a specific
item. And three functions--RASSOC, RASSOC-IF, and RASSOC-IF-NOT--work
just like the corresponding ASSOC functions except they use the value
in the CDR of each element as the key, performing a reverse lookup.
很明显,使用 ASSOC
搜索一个关联表所花的时间是当匹配的对被发现时当前列表深度的函数。在最坏情况下,检测到没有匹配的对将需要
ASSOC 扫描关联表的每一个元素。但由于关联表的基本机制是如此轻量,故而对于小型的表来说,关联表可以在性能上超过哈希表。另外,关联表在如何做查询方面也提供了更大的灵活性。我已经提到了
ASSOC 接受
:key 和 :test
关键字参数。当这些还不能满足你的需要时,可以使用 ASSOC-IF 和
ASSOC-IF-NOT 函数,其返回 CAR 部分满足(或不满足,在
ASSOC-IF-NOT 的情况下)传递到指定项上的测试函数的第一个键值对。并且还有另外
3 个函数,即 RASSOC、RASSOC-IF 和 RASSOC-IF-NOT,和对应的
ASSOC 系列函数相似,只是它们使用每个元素的
CDR 中的值作为键,从而进行反向查询。
The function COPY-ALIST is similar to COPY-TREE except, instead of copying the whole tree structure, it copies only the cons cells that make up the list structure, plus the cons cells directly referenced from the CARs of those cells. In other words, the original alist and the copy will both contain the same objects as the keys and values, even if those keys or values happen to be made up of cons cells.
函数 COPY-ALIST 与 COPY-TREE 相似,除了代替复制整个树结构,它只复制那些构成列表结构的点对单元,外加那些单元的 CAR 部分直接引用的点对单元。换句话说,原先的关联表和它的副本将同时含有相同的对象作为键和值,哪怕这些键或值刚好也由点对单元构成也是如此。
Finally, you can build an alist from two separate lists of keys and values with the function PAIRLIS. The resulting alist may contain the pairs either in the same order as the original lists or in reverse order. For example, you may get this result:
最后,你可以从两个分开的键和值的列表中用函数 PAIRLIS 构造出一个关联表。返回的关联表可能含有与原先列表相同或相反顺序的键值对。例如,你可能得到下面这样的结果:
CL-USER> (pairlis '(a b c) '(1 2 3))
((C . 3) (B . 2) (A . 1))Or you could just as well get this:
或者你也可能得到下面这样的效果:
CL-USER> (pairlis '(a b c) '(1 2 3))
((A . 1) (B . 2) (C . 3))The other kind of lookup table is the property list, or plist, which
you used to represent the rows in the database in
Chapter 3. Structurally a plist is just a regular list with the keys
and values as alternating values. For instance, a plist mapping A, B,
and C, to 1, 2, and 3 is simply the list (A 1 B 2 C 3). In
boxes-and-arrows form, it looks like this:
另一类查询表是属性表(plist),你曾经在第 3
章里用它来表示数据库中的行。从结构上来讲,属性表只是一个正常的列表,其中带有交替出现的键和值作为列表中的值。例如,一个将
A、B 和 C
分别映射到 1、2 和 3 的属性表就是一个简单的列表
(A 1 B 2 C 3)。用方框和箭头的形式来表示,它看起来像这样:

However, plists are less flexible than alists. In fact, plists support only one fundamental lookup operation, the function GETF, which takes a plist and a key and returns the associated value or NIL if the key isn't found. GETF also takes an optional third argument, which will be returned in place of NIL if the key isn't found.
不过,属性表不像关联表那么灵活。事实上,属性表仅支持一种基本查询操作,即函数 GETF,其接受一个属性表和一个键,返回所关联的值或是在键没有被找到时返回 NIL。GETF 也接受一个可选的第三个参数,它将在键没有被找到时代替 NIL 作为返回值。
Unlike ASSOC, which uses EQL as its default test and allows a
different test function to be supplied with a :test argument, GETF
always uses EQ to test whether the provided key matches the keys in
the plist. Consequently, you should never use numbers or characters as
keys in a plist; as you saw in Chapter 4, the behavior of EQ for those
types is essentially undefined. Practically speaking, the keys in a
plist are almost always symbols, which makes sense since plists were
first invented to implement symbolic "properties," arbitrary mappings
between names and values.
与 ASSOC 不同,其使用 EQL 作为默认测试并允许通过 :test
参数提供一个不同的测试函数,GETF 总是使用 EQ
来测试所提供的键是否匹配属性表中的键。因此,你一定不能用数字和字符作为属性表中的键。正如你在第
4 章里看到的那样,EQ
对于这些类型的行为在本质上是未定义的。从实践上来讲,一个属性表中的键差不多总是符号,这是合理的,因为属性表最初被发明用于实现符号
“属性”,即名字和值之间的任意映射。
You can use SETF with GETF to set the value associated with a given key. SETF also treats GETF a bit specially in that the first argument to GETF is treated as the place to modify. Thus, you can use SETF of GETF to add a new key/value pair to an existing plist.
你可以将 SETF 与 GETF 一起使用来设置与给定键所关联的值。SETF 也会稍微特别地对待 GETF,GETF 的第一个参数被视为将要修改的位置。这样,你可以使用 GETF 的 SETF 来向一个已有的属性表里添加新的键值对。
CL-USER> (defparameter *plist* ())
*PLIST*
CL-USER> *plist*
NIL
CL-USER> (setf (getf *plist* :a) 1)
1
CL-USER> *plist*
(:A 1)
CL-USER> (setf (getf *plist* :a) 2)
2
CL-USER> *plist*
(:A 2)To remove a key/value pair from a plist, you use the macro REMF, which sets the place given as its first argument to a plist containing all the key/value pairs except the one specified. It returns true if the given key was actually found.
为了从属性表里移除一个键值对,你可以使用宏 REMF,它将作为其第一个参数给定的位置设置成含有除了指定的那一个以外的所有键值对的属性表。当给定的键被实际找到时,它返回真。
CL-USER> (remf *plist* :a)
T
CL-USER> *plist*
NILLike GETF, REMF always uses EQ to compare the given key to the keys in the plist.
和 GETF 一样,REMF 总是使用 EQ 来比较给定的键和属性表中的键。
Since plists are often used in situations where you want to extract several properties from the same plist, Common Lisp provides a function, GET-PROPERTIES, that makes it more efficient to extract multiple values from a single plist. It takes a plist and a list of keys to search for and returns, as multiple values, the first key found, the corresponding value, and the head of the list starting with the found key. This allows you to process a property list, extracting the desired properties, without continually rescanning from the front of the list. For instance, the following function efficiently processes--using the hypothetical function process-property--all the key/value pairs in a plist for a given list of keys:
由于属性表经常被用于从同一个属性表中抽取出几个不同属性的场合,所以
Common Lisp 还提供了一个函数 GET-PROPERTIES,它能够高效地从单一
属性表中抽取多个值。它接受一个属性表和一个需要被搜索的键的列表,并返回多个值:第一个被找到的键、其对应的值,以及一个以被找到的键开始的列表的头部。这可以允许你处理一个属性表,抽取出想要的属性,而无需持续地从列表的开始处重新扫描。例如,下面的函数使用假想的函数
process-property 有效地处理用于指定键列表的属性表中的所有键值对:
(defun process-properties (plist keys)
(loop while plist do
(multiple-value-bind (key value tail) (get-properties plist keys)
(when key (process-property key value))
(setf plist (cddr tail)))))The last special thing about plists is the relationship they have with symbols: every symbol object has an associated plist that can be used to store information about the symbol. The plist can be obtained via the function SYMBOL-PLIST. However, you rarely care about the whole plist; more often you'll use the functions GET, which takes a symbol and a key and is shorthand for a GETF of the same key in the symbols SYMBOL-PLIST.
关于属性表,最后特别要指出的是它们与符号之间的关系:每一个符号对象都有一个相关联的属性表用来保存关于该符号的信息。这个属性表可以通过函数 SYMBOL-PLIST 获取到。但你很少需要关心整个属性表;更常见的情况是使用函数 GET,其接受一个符号和一个键,功能相当于在符号的 SYMBOL-PLIST 上对同一个键使用 GETF。
(get 'symbol 'key) === (getf (symbol-plist 'symbol) 'key)Like GETF, GET is SETFable, so you can attach arbitrary information to a symbol like this:
和 GETF 一样,GET 也可以用 SETF 来操作,因此你可以像下面这样将任意信息附加到一个符号上:
(setf (get 'some-symbol 'my-key) "information")To remove a property from a symbol's plist, you can use either REMF of SYMBOL-PLIST or the convenience function REMPROP.
为了从一个符号的属性表中移除属性,你可以使用 SYMBOL-PLIST 上的 REMF 或是更便捷的函数 REMPROP。
(remprop 'symbol 'key) === (remf (symbol-plist 'symbol key))Being able to attach arbitrary information to names is quite handy when doing any kind of symbolic programming. For instance, one of the macros you'll write in Chapter 24 will attach information to names that other instances of the same macros will extract and use when generating their expansions.
向名字中附加任意信息对于任何类型的符号编程来说都是很有用的。例如,第 24 章里我们将编写一个宏,它将向名字中附加信息,以便同一个宏的其他实例能将其抽取出并用于生成它们的展开式。